When Sora steps aside: what is OpenAI choosing?
It's all about compute. Reading OpenAI's Sora wind-down through the CFO's public numbers — 0.2GW → 1.9GW, ARR 2B → 20B+ — as a resource-allocation choice, not a product failure.

2026 年 4 月,OpenAI 先后确认:Sora web/app 将在 4 月 26 日 停用,Sora API 将在 9 月 24 日 停用。[1] 几天前,Sam Altman 在接受 Laurie Segall 采访时,被问到为什么连 Sora 这样的产品也会被关掉,他给出的回答很短,甚至有点冷:It’s all about compute. [3]
这句话值得反复琢磨,因为它把一件看起来像产品新闻的事,直接拉回了资源分配。一个曾经最能代表 OpenAI 想象力的产品让路,意味着问题已经不再是“视频生成酷不酷”,而是“在一个资源极其稀缺的阶段,什么值得继续投入,什么必须往后排”。
如果把 Sora 的停用放进 OpenAI 过去一年的公开表述里看,这件事就不只是一轮产品收缩,更像一次战略选择的显影。透过它,能看到 OpenAI 现在的处境,也能看到它接下来大概率会怎么选。
Sora 关掉的,到底是什么
Sora 这一轮变化,包含两个层次。
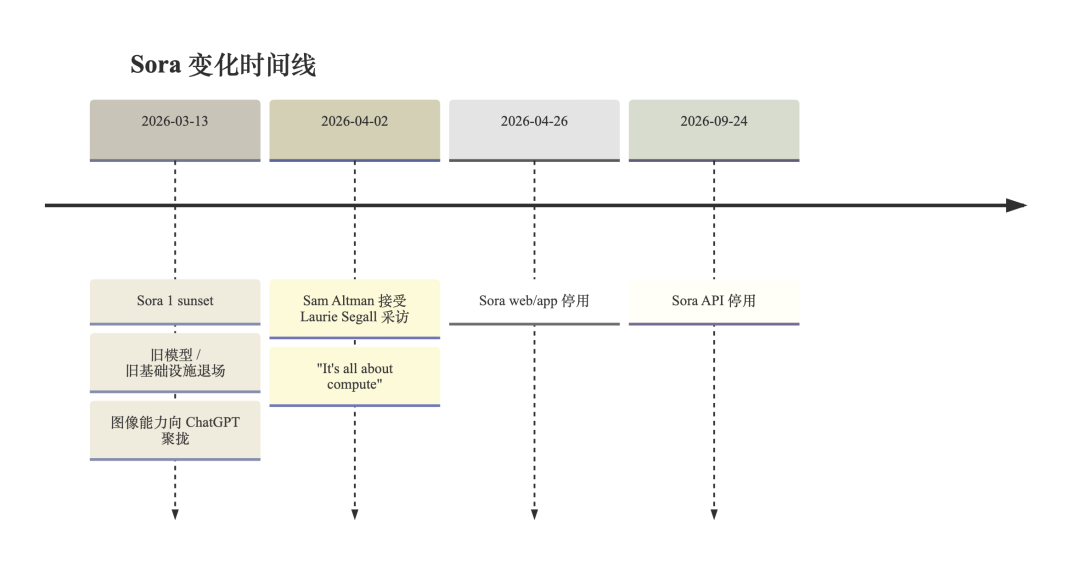
第一个层次,是 Sora 1 的退场。OpenAI 在帮助中心的《Sora 1 Sunset – FAQ》里写得很清楚:Sora 1 从 2026 年 3 月 13 日起在美国不可用,原因是它依赖旧模型和旧基础设施,OpenAI 要把体验收敛到单一的 Sora 2 上,以减少复杂度并继续改进。[2] 同一份 FAQ 还写到,Sora 1 里的图片生成功能也会下线,相关能力会转移到 ChatGPT。[2]
第二个层次,才是更大的 Sora discontinuation。OpenAI 后续又单独发布停用说明,明确写明 Sora web/app 的停止时间,以及 Sora API 的截止时间,并要求用户在此之前导出内容。[1] 这就不再只是“旧版本退场、新版本接上”那么简单了。它更接近一次明确的产品生命周期终止。
把这两步连起来看,意思就出来了:OpenAI 没有退出视频生成这个方向,它收掉的是 Sora 作为独立产品线的存在方式。 入口被收走,独立形态被收走,为这条线单独配置资源的必要性也一起消失了。
Sam 那句 It’s all about compute,落到实处,就是这里。Sora 不是因为不够酷才被让路,恰恰是因为它足够酷、足够显眼,才更能说明问题:连这种级别的产品都可以被收掉,说明 OpenAI 内部的资源排序已经变了。
为什么一句 compute,能解释这么多事
很多人第一次听到这句话时,都会下意识怀疑:这是不是一个太方便的解释?好像任何东西做不下去,都可以说是因为算力紧张。
可到了 2026 年,compute 早就不只是“GPU 很贵”这么简单。 OpenAI 自己已经把这件事说得很直接。2026 年 1 月,OpenAI CFO Sarah Friar 在《A business that scales with the value of intelligence》中写道:Compute is the scarcest resource in AI. 她同时披露,OpenAI 的 available compute 在 2023 到 2025 年间从大约 0.2GW 增长到约 1.9GW,同期 ARR 从 20 亿美元 增长到 200 亿美元以上,并明确表示:如果有更多算力,OpenAI 的客户采用和商业化本来还可以更快。[4]
关键不在某个具体数字,而在于 OpenAI 公开使用这组数字的方式。它强调的不是“我们成本很高”,而是“算力直接限制了我们增长有多快”。在 OpenAI 的经营语境里,算力不是普通后台成本,而是增长约束项(也就是决定你能跑多快的关键资源)。
所谓“算力紧张”,至少包含三件事。
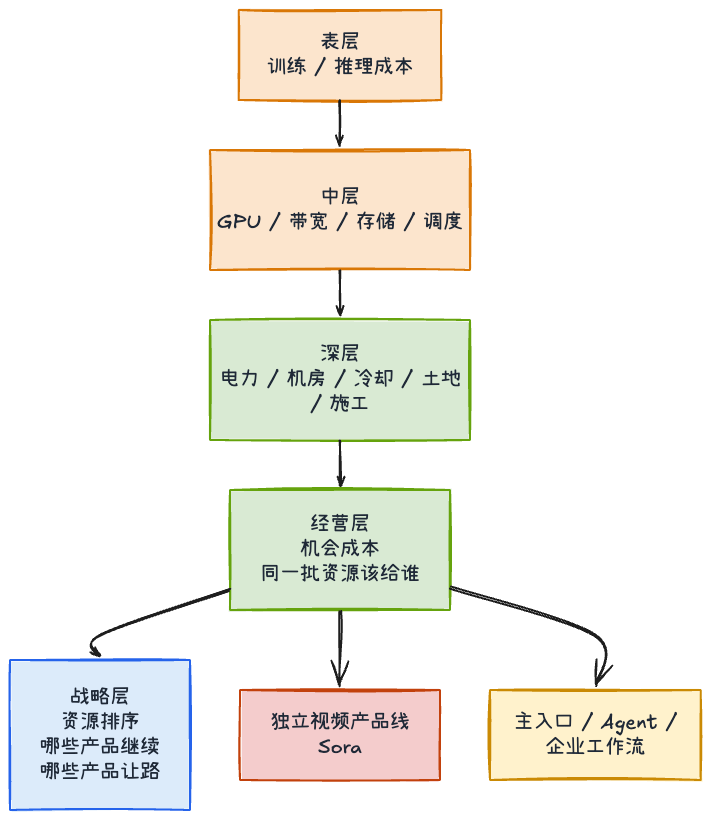
第一,是推理和训练本身就贵。 视频生成、多模态推理、长链路 agent 任务,本来就是单位成本最高的一类能力。它们不仅消耗 GPU,也更吃带宽、存储、调度和系统稳定性。一个独立的视频产品,如果要长期、稳定、面向大量用户地提供服务,天然就比纯文本聊天重得多。
第二,是今天的瓶颈已经不只在芯片。 美国能源部在 2024 年 12 月的报告里提到,数据中心在 2023 年已经消耗美国总电力的 4.4%,到 2028 年这一比例可能升到 6.7% 到 12%。[5] 这背后的意思非常现实:哪怕 GPU 供给改善,你也仍然可能被电力接入、变压器、冷却、机房建设、区域配电和土地审批卡住。所谓“算力”,最后会一路落到物理世界。
第三,也是最容易被忽视的一层,是机会成本(同样一批资源投在 A 上,就不能同时投在 B 上)。这对 OpenAI 尤其关键。对它来说,更难的问题不是“能不能继续做 Sora”,而是“同样一批算力,应该继续给 Sora,还是给下一代模型、ChatGPT、agent、企业工作流和更高频的推理请求”。
假设同样一批算力,既可以支持一个独立的视频生成产品继续跑,也可以拿去提升 ChatGPT 里每天都会被调用的高频能力,比如代码工作流、任务自动化,或者企业客户愿意持续付费的推理服务。对于一家正在争夺默认入口(用户一想到 AI 就先打开的那个产品)的公司来说,后者通常更容易形成留存、合同和长期飞轮(越用越强、越强越能带来更多用户和收入的循环)。这不是说视频生成没有价值,而是说在资源有限时,它未必总能排在最前面。
所以,Sam 那句 It’s all about compute 说的并不只是“我们缺几张卡”,而是“这家公司已经走到必须围绕最稀缺资源做排序的阶段”。
Sora 背后,变的是 OpenAI 自己
如果事情只是“视频太贵”,那它最多是一条产品线的损益问题。Sora 值得细看,是因为它背后折射出的,已经是 OpenAI 的公司形态和战略位置都在变化。
先变的,是 OpenAI 的经营方式。2026 年 3 月 31 日,OpenAI 在融资公告里写到,公司已经拿到 1220 亿美元 committed capital,另有数十亿美元未动用信贷额度;同一份公告还写明,当时 OpenAI 的月收入 run-rate 已达到 20 亿美元,ChatGPT 周活跃用户超过 9 亿。[8] 这些数字放在一起,已经很难再把 OpenAI 理解成一个“先做研究、再慢慢想商业化”的实验室。它正在向一种平台化组织靠拢:不仅要训练模型,还要筹措资本、锁定算力、维护入口、推动分发,并尽量把这些环节接成一个闭环。
这里的“平台化”,不是说 OpenAI 已经像 AWS 那样完整拥有并运营底层基础设施,也不是说它已经变成传统意义上的云厂商或能源公司。更准确地说,它开始同时处理几类过去常常分属不同公司的任务:一边训练和发布模型,一边筹措巨额资本,一边通过合作伙伴去锁定芯片、数据中心、土地和电力资源,再把这些资源通过 ChatGPT、API 和企业产品变成用户关系与收入。Stargate 正是一个很典型的例子。OpenAI 在官方公告里谈的已经不只是模型,而是融资方、技术伙伴、园区选址、土地、电力、施工和数据中心建设。[6]
可这一切发生时,OpenAI 仍然远远谈不上轻松。Reuters 在 2025 年 3 月的报道中提到,OpenAI 预计到 2029 年前 都不会实现现金流转正,原因包括芯片、数据中心和人才成本持续高企。[9] 这意味着 OpenAI 现在面对的,不是“有没有收入”,而是“增长极快,但消耗资源的速度也极快”。在这种阶段,组织不可能无限平行扩张。再酷的产品,只要不能直接服务主线,就会开始被重新审视。
与此同时,OpenAI 的主线本身也变了。近几次公开表述里,它谈得越来越多的是 agents、workflow automation(工作流自动化,也就是把一连串实际任务交给系统连续完成)、distribution 和 infrastructure。[4][8] 这说明 OpenAI 的注意力,正在从“做出下一个最惊艳的 demo”,转向“怎样把 AI 变成默认工作流”。这会直接改变资源排序。能支撑 ChatGPT 成为主入口、能支撑 agent 进入真实任务、能支撑企业高频使用的能力,会比一个很有想象力但相对独立的产品更靠前。
还有一个经常被忽略的变化,是竞争的重心也在移动。OpenAI 今天面对的,已经不只是模型竞争,也是入口竞争。微软在 2026 年 3 月公开写明,Copilot is model diverse by design,同时调用 OpenAI 和 Anthropic 的模型。[10] Google 则在 Search、Chrome、Gmail、Workspace 等默认入口里持续塞进 Gemini,并展示多步骤任务能力。[11] 这背后的压力也很清楚:如果 OpenAI 不能把自己的入口做得足够强,它就随时可能被重新压回“别人平台上的模型供应商”(只负责提供模型能力,却不掌握最终用户关系和默认入口)的位置。
这样看,Sora 的停用就不是一件孤立的小事了。它更像一次组织收敛,一次公开的自我修正。OpenAI 的动作已经说明,它现在更在乎的是哪条路最能通向主入口、主工作流和更强的资源控制力,而不是哪条路最能制造下一次惊艳感。
OpenAI 接下来会把资源押向哪里
接下来看的,就是资源往哪边流。
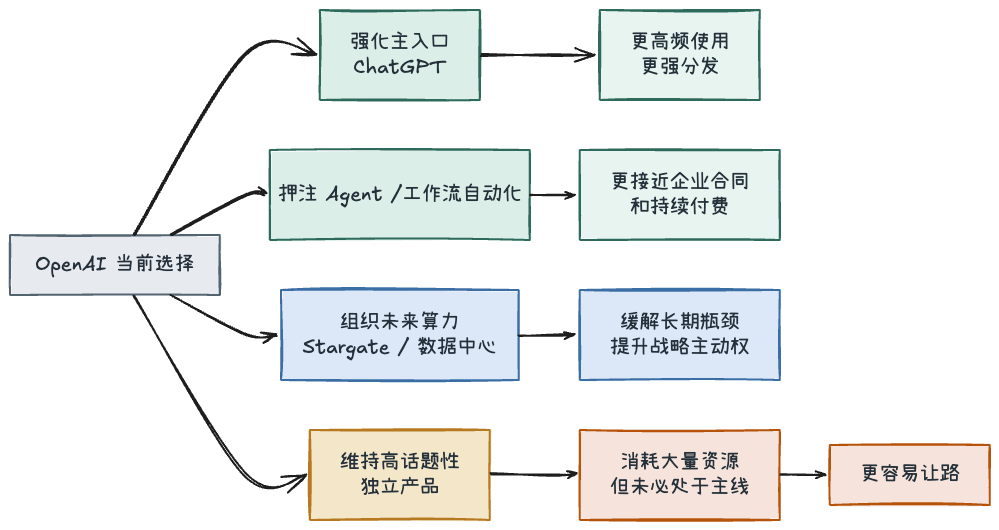
接下来,ChatGPT 仍会被往“默认入口”的位置推。入口不只是流量问题,更是议价权问题。谁先成为用户默认打开的那个 AI 产品,谁就更有机会把模型能力、agent、搜索、代码、企业协作和后续所有新能力叠在同一个界面里。
算力问题也会继续被往基础设施层去解。Stargate 不是一个象征性项目,而是一种很强的表态:OpenAI 不准备只做一家依赖外部供给的模型公司,而是想更深地参与未来几年产能的组织。[6][7] 这条路能不能完全走通,现在当然没人知道;但至少从公开动作看,OpenAI 已经接受了一个现实,AI 的竞争越来越像一场工业系统竞争,而不只是算法竞争。
资源也会继续往更接近真实工作流的方向压。从 OpenAI 自己的文字看,未来重点是 agents and workflow automation。[4] 这不是说多模态不重要,也不是说视频没有前景,而是说在这个阶段,离高频使用、企业合同、持续付费更近的能力,会更容易拿到优先级。
这也意味着,OpenAI 很可能会越来越习惯做一种过去不那么符合它公众形象的事:主动砍掉一些很酷、很有话题性、但在主线排序里不够靠前的产品或形态。Sora 只是第一个足够醒目的例子,不一定会是最后一个。
结语:Sora 被关,不是在回答视频,而是在回答 OpenAI 想成为什么
关于 Sora,最容易说出口的故事是“视频生成太贵,所以 OpenAI 关了它”。这句话不算错,但还不够。更值得注意的是,当一家以创造惊艳感著称的公司,开始主动关掉自己最有惊艳感的产品之一,它其实是在告诉外界:决定下一轮竞争的,已经不只是能力展示,而是稀缺资源如何被组织、如何被分配、又如何被转化成入口和收入。
Sora 的停用不只是一次产品退场。 它更像一份公开的战略样本,让人看到 OpenAI 眼里的未来正在变化。它想要的,已经不只是不断做出新能力,而是尽可能把模型、算力、基础设施和主入口接成一个更完整的闭环。
Sam 说,It’s all about compute.
把这句话放回 Sora 这件事里,它表达的也许不是焦虑,而是一种选择:当资源有限时,OpenAI 决定把它们押在自己认为更接近未来主航道的地方。
Sora 这件事的价值,也许就在这里。 它让人看到的,不是一款产品怎么结束,而是一家公司正在变成什么。
References
[1]: https://help.openai.com/en/articles/20001152-what-to-know-about-the-sora-discontinuation
[2]:https://help.openai.com/en/articles/20001071-sora-1-sunset-faq
[3]:https://www.iheartmedia.com/press/veteran-tech-journalist-and-mostly-human-ceo-laurie-segall-sits-down-exclusively-openai-ceo
[4]:https://openai.com/index/a-business-that-scales-with-the-value-of-intelligence/
[5]:https://www.energy.gov/articles/doe-releases-new-report-evaluating-increase-electricity-demand-data-centers
[6]:https://openai.com/index/announcing-the-stargate-project/
[7]:https://openai.com/index/stargate-advances-with-partnership-with-oracle/
[8]:https://openai.com/index/accelerating-the-next-phase-ai/
[9]:https://finance.yahoo.com/news/openai-does-not-expect-cash-191503509.html
[10]:https://blogs.microsoft.com/blog/2026/03/09/introducing-the-first-frontier-suite-built-on-intelligence-trust/
[11]:https://blog.google/innovation-and-ai/products/google-ai-updates-january-2026/
[12]:https://www.anthropic.com/news/anthropic-amazon-trainium
[13]: https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services