Inside Claude Code, part 1: the multi-agent architecture
A 18K-word reverse-engineering of Claude Code's npm package source map. Three agent shapes — Subagent, Coordinator, Swarm — and why Anthropic chose this structure.

基于 @anthropic-ai/claude-code v2.1.88 npm 包 source map 还原的 TypeScript 源码分析
阅读说明
本文混合了三类信息:
- Anthropic 官方公开文档中明确说明的能力
- 当前版本源码中可以观察到的实现细节
- 对源码行为的推断
其中第 2、3 类不等于 Anthropic 对外承诺的稳定 API / 产品规范,后续版本可能调整。
前言
如果你在做 AI Agent,你可能遇到过这些问题:
- 单个 Agent 处理复杂任务时,context window 不够用
- 想"并行处理"多个子任务,但不知道怎么编排
- 多个 Agent 之间怎么通信、怎么共享状态、怎么不互相干扰
Claude Code 是目前工程化较成熟的 coding agent 之一。它在这些问题上给出了很强的工程化实现。这篇文章会从源码层面拆解它的做法,并尽量区分“公开能力”和“内部实现”。
一、核心设计:Agent 就是一个普通工具
Claude Code 的关键洞察
模型不需要理解"多 Agent"。对模型来说,调 Agent 和调 Bash 没有任何区别。
每次调 Anthropic API,请求长这样:
{
"system": "你是 Claude Code...",
"messages": [...],
"tools": [
{ "name": "Bash", "description": "执行命令...", "input_schema": {...} },
{ "name": "Read", "description": "读文件...", "input_schema": {...} },
{ "name": "Agent", "description": "启动子代理...", "input_schema": {
"prompt": "string",
"subagent_type": "string (optional)",
"run_in_background": "boolean (optional)"
}
}
]
}Agent 在 tools 数组里和 Bash、Read 并列。模型想派生子代理,就调 Agent 工具,传一个 prompt,等结果回来。就像调 Bash 传一个命令,等输出回来一样。
所有的多 Agent 复杂度——上下文隔离、后台执行、消息通知——都在工具实现内部,对模型完全透明。
这为什么好
大部分 AI 编排框架失败在:给模型引入了一个新概念("Agent"、"Worker"、"Team"),模型需要学习新的交互模式。Claude Code 不引入新概念——模型只需要会一件事:调工具,传参数,等结果。
二、三种 Agent 形态的全景
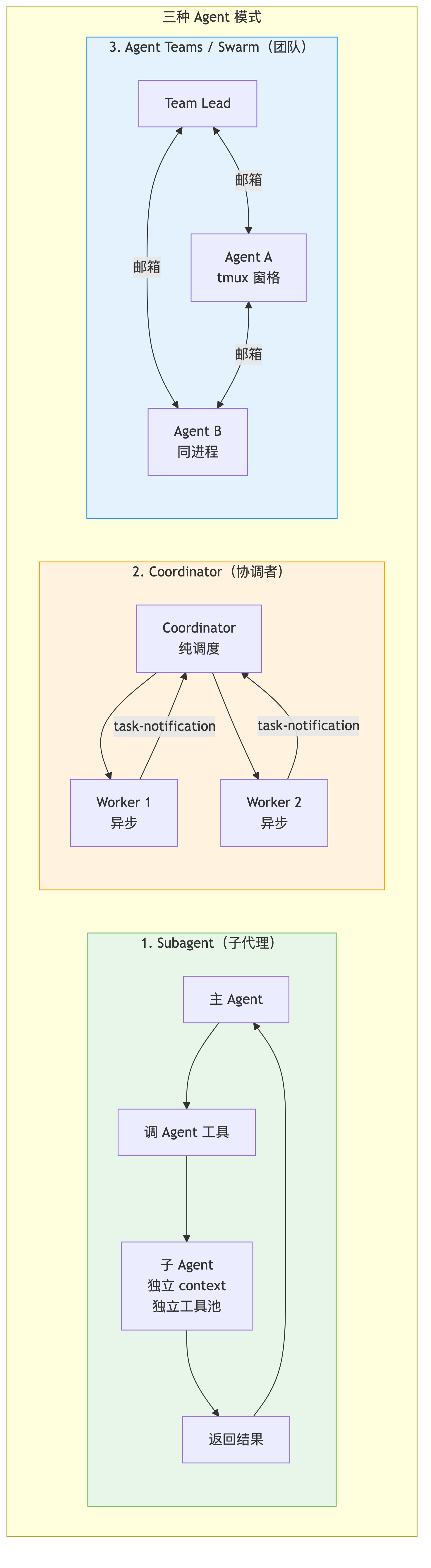
| 形态 | 拓扑 | 谁干活 | 通信方式 | 适用场景 |
|---|---|---|---|---|
| Subagent | 主 Agent 调子 Agent | 子 Agent 干活,主 Agent 等或异步收结果 | Tool Result / <task-notification> | 派生一个子任务 |
| Coordinator | 星型,一个中心 | Coordinator 调度,Worker 干活 | <task-notification> + SendMessage | 大任务拆分、并行研究 |
| Agent Teams / Swarm | 团队制,存在 team lead | Team lead 和 teammates 协作 | 文件邮箱 | 长期协作、多终端团队执行 |
三、Subagent(子代理)——最基础的 Agent 模式
3.1 模型怎么调用的
模型调用 Agent 工具时传入:
{
"description": "修复 auth bug", // 3-5 词,UI 上显示用
"prompt": "在 src/auth/validate.ts:42 修复空指针...", // 子代理看到的完整指令
"subagent_type": "general-purpose", // 可选,指定 Agent 类型
"model": "sonnet", // 可选,指定模型
"run_in_background": false // 可选,是否后台运行
}3.2 Agent 类型
在你提供的这份源码里,可见的内置 Agent 如下:
| Agent 类型 | 用途 | 工具权限 |
|---|---|---|
general-purpose | 通用子代理(默认) | 全部工具 |
Explore | 代码库快速探索 | 禁用 Agent、ExitPlanMode、Edit、Write、NotebookEdit;可做只读探索 |
Plan | 规划实现方案 | 除 Agent、ExitPlanMode、Edit、Write、NotebookEdit 外的全部工具(不可写文件) |
claude-code-guide | Claude Code / API 使用指南查询 | Glob、Grep、Read、WebFetch、WebSearch |
statusline-setup | 状态栏配置 | Read、Edit |
verification | 测试/验证 | 特性门控,可见于当前源码,但不一定在所有环境开启 |
说明
Explore和Plan在源码中受特性开关控制,不保证所有环境都可见verification也受特性门控,不应写成“所有用户都稳定可用”- 当前源码中没有文中原先写的
project-inspector
还可以从 .claude/agents/*.md 加载自定义 Agent,通过 YAML frontmatter 定义工具权限、模型、最大轮次、是否默认后台执行等。
3.3 执行流程
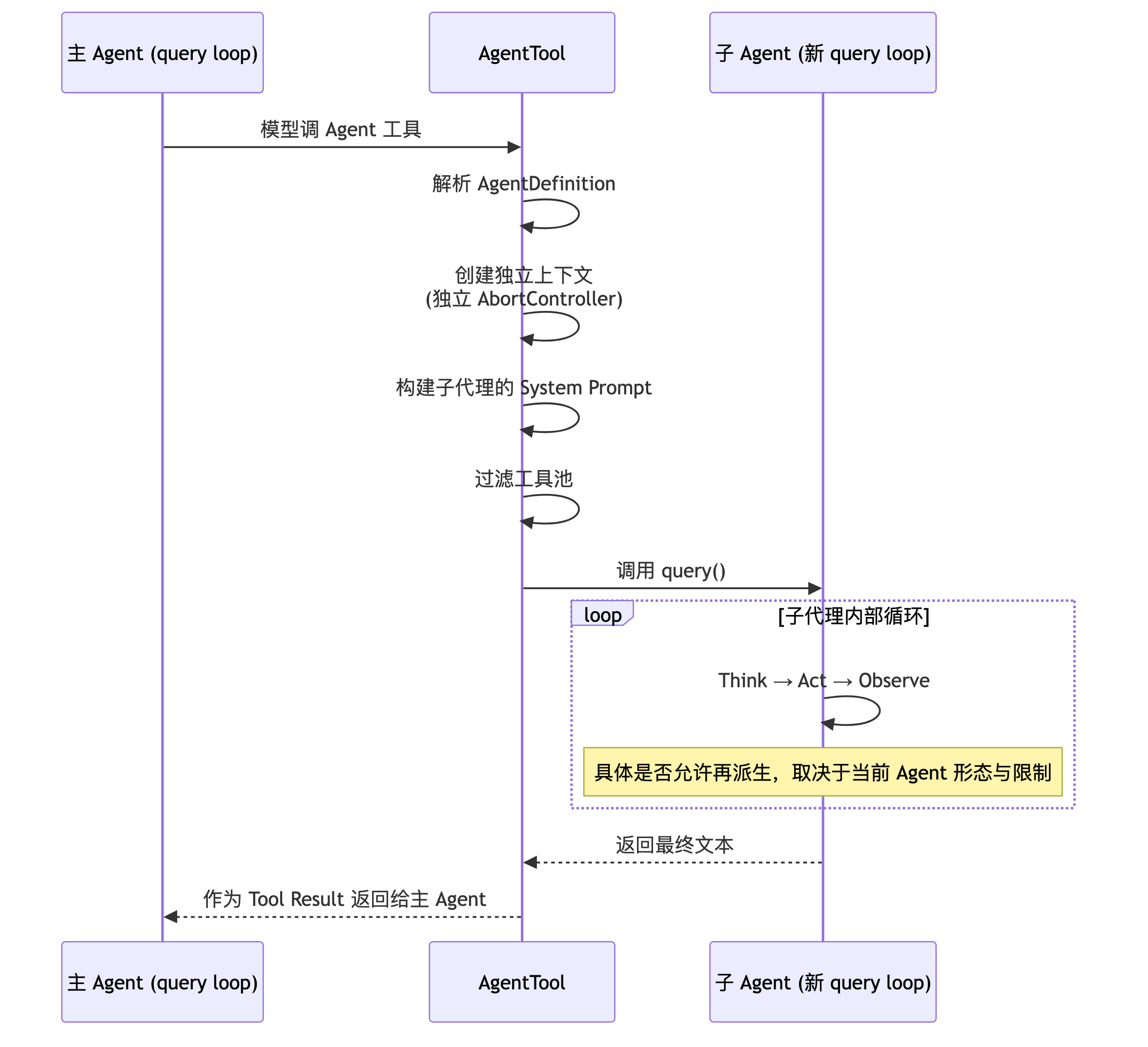
runAgent() 内部确实会调用 query()。但“因此支持任意深度嵌套”这个结论过头了:
- Anthropic 官方公开文档对 subagents 的说法是:subagents 不能再生成 subagents
- 当前源码里至少有一条明确限制:fork worker 不能再次 fork
- 因此,比较稳妥的表述应该是:
runAgent()是递归式实现,但不要把它理解成对外公开保证的“无限套娃子代理能力”
3.4 上下文隔离
每个子代理通常会有独立环境,但原文“完全隔离、只看到 prompt”需要收紧:
- System Prompt:根据 Agent 类型重新构建
- 工具池:根据 AgentDefinition 过滤(Explore 只有只读工具)
- 对话历史:常规 Agent 调用应按“fresh start”理解;但 fork 路径在当前源码里会继承上下文
- AbortController:独立,可以单独取消
所以更准确的说法是:
- 对普通 Agent 调用,应该按“子代理看不到完整父级对话,需要在 prompt 里自包含地交代任务”来理解
- 但并不是所有内部路径都只有一个孤立
prompt;至少 fork worker 在源码中就有“继承上下文”的实现
Claude Code 的 Agent 工具说明中对常规 Agent 调用有明确描述:
Each Agent invocation starts fresh — provide a complete task description.
Brief the agent like a smart colleague who just walked into the room — it hasn't seen this conversation, doesn't know what you've tried, doesn't understand why this task matters.
这也是 Coordinator 系统提示中"理解不可委托"原则的重要原因——Worker 不应被假定能看到 Coordinator 之前收到的上下文,Coordinator 需要把必要信息显式写进 prompt。
3.5 与主 Agent 的通信:单向返回
子代理是单向通信——拿到 prompt 后开始干活,干完把结果交回去:
主 Agent → 子代理:prompt 参数(创建时一次性传入)
子代理 → 主 Agent:Tool Result(前台)或 task-notification(后台)
前台子代理:结果作为 Tool Result 返回,和调 Bash 返回命令输出一样。
后台子代理:立即返回 status: 'async_launched',结果稍后通过 <task-notification> XML 注入主 Agent 的对话中。
注意:通知不是 Worker 自己写的。 Worker 只是正常输出最终文本,系统在 Worker 完成后由 enqueueAgentNotification()(LocalAgentTask.tsx)构建通知——先用 extractTextContent() 提取 Worker 最后一条 assistant 消息的纯文本作为 <result>,再打包 taskId、status、summary、usage 等字段成 XML。Worker 本身不知道通知的存在。
<task-notification>
<task-id>agent-a1b</task-id>
<output-file>/tmp/claude-uid/proj/session/subagents/agent-a1b.md</output-file>
<status>completed</status>
<summary>Agent "修复 auth bug" completed</summary>
<result>已修复空指针,commit abc123</result>
<usage>
<total_tokens>12450</total_tokens>
<tool_uses>8</tool_uses>
<duration_ms>34200</duration_ms>
</usage>
</task-notification>主 Agent 通过 TaskOutput 工具读取 <output-file> 路径可以获得完整 transcript。但主 Agent 看不到 Worker 的中间过程——只看到通知里封装好的内容。
子代理不能中途和主 Agent 对话。如果主 Agent 想追加指令,需要用 SendMessage 工具。
3.6 自动转后台(有条件)
源码里确实存在 120 秒自动后台 的逻辑,但它不是无条件规则,而是受环境变量 / feature gate 控制:
- 开启
CLAUDE_AUTO_BACKGROUND_TASKS或相应特性门控时,阈值为 120 秒 - 未开启时,这条行为并不成立
3.7 后台代理的进度追踪
后台代理每 ~30 秒做一次 fork 摘要:fork 当前对话,禁用所有工具(只看不动手),让模型输出 3-5 词进度描述(如 "Fixing null check in validate.ts"),显示在 UI 的进度条上。
四、Coordinator 模式——中心化调度
4.1 是什么
Coordinator 模式下,一个 Claude 实例当纯调度员。它自己不写代码,只做三件事:拆任务、派 Worker、汇总结果。
通过环境变量 CLAUDE_CODE_COORDINATOR_MODE=1 激活。
4.2 Coordinator 的工具
Coordinator 有 4 个工具(第 4 个按需出现):
| 工具 | 作用 |
|---|---|
Agent | 生成 Worker |
SendMessage | 继续一个已有 Worker |
TaskStop | 停止一个 Worker |
subscribe_pr_activity / unsubscribe_pr_activity | 订阅 / 取消订阅 GitHub PR 事件(如有) |
4.3 约 252 行的系统提示——Claude Code 最精妙的提示工程
Coordinator 的系统提示约 252 行(源码文件总行数 370 行,提示内容从第 116 行起),不是简单说"你是个协调者",而是手把手教模型怎么当调度员。
标准工作流

原文(
coordinatorMode.ts第 200 行)
| Phase | Who | Purpose |
|---|---|---|
| Research | Workers (parallel) | Investigate codebase, find files, understand problem |
| Synthesis | You (coordinator) | Read findings, understand the problem, craft implementation specs |
| Implementation | Workers | Make targeted changes per spec, commit |
| Verification | Workers | Test changes work |
"理解不可委托"原则
这是 Coordinator 模式最核心的设计规则:
Workers can't see your conversation. Every prompt must be self-contained.
Never write "based on your findings" or "based on the research." These phrases delegate understanding to the worker.
协调者收到 Worker 的研究结论后,必须自己读懂,然后写一个包含具体文件路径、行号、修改内容的实现 spec 给下一个 Worker。
❌ 反面教材:
Agent({ prompt: "Based on your findings, fix the auth bug" })
✅ 正确做法:
Agent({ prompt: "Fix the null pointer in src/auth/validate.ts:42.
The user field on Session (src/auth/types.ts:15) is undefined when
sessions expire but the token remains cached. Add a null check
before user.id access — if null, return 401 with 'Session expired'.
Commit and report the hash." })
"继续 vs 重新生成"的决策表
Worker 完成任务后,协调者要决定是继续这个 Worker(SendMessage),还是生成新的(Agent):
| 情况 | 决策 | 原因 |
|---|---|---|
| Worker 研究了需要编辑的文件 | 继续 | 上下文已加载 |
| 研究广但实现窄 | 新建 | 避免拖入探索噪音 |
| 修正失败或扩展近期工作 | 继续 | Worker 有错误上下文 |
| 验证不同 Worker 写的代码 | 新建 | 验证者需要新视角 |
| 第一次用错了方法 | 新建 | 错误上下文污染重试 |
| 完全不相关的任务 | 新建 | 没有可复用的上下文 |
并发规则
Parallelism is your superpower. Workers are async.
- 只读任务(研究)→ 随便并行
- 写任务(实现)→ 同一组文件一次只能一个
- 验证 → 可和实现并行(不同文件区)
Worker 的结果通知——每个字段是谁生成的
Worker 完成后,系统构建 <task-notification> XML,注入 Coordinator 的对话中。Worker 本身不知道通知的存在——它只是正常完成对话,系统在后台做提取和包装。
具体的数据流(源码 agentToolUtils.ts → AgentTool.tsx → LocalAgentTask.tsx):
Worker 对话结束
↓
finalizeAgentTool() 找到 Worker 的最后一条 assistant 消息
↓ 从中过滤 type === 'text' 的 content block
↓
extractTextContent() 把文本块用 \n 拼成纯字符串 → finalMessage
↓
enqueueAgentNotification() 组装 XML 通知
↓ 注入 Coordinator 的对话
通知中每个字段的来源
| 字段 | 谁生成的 | 说明 |
|---|---|---|
<task-id> | 系统 | Worker 启动时分配的 ID |
<output-file> | 系统 | Worker transcript 文件路径,始终存在 |
<status> | 系统 | completed / failed / killed,取决于 Worker 执行结果 |
<summary> | 系统模板生成 | 固定格式 Agent "${description}" completed,其中 description 来自 Coordinator 启动 Worker 时传的参数 |
<result> | Worker 模型的最终输出 | 从 Worker 最后一条 assistant 消息中提取纯文本(extractTextContent),Worker 不知道自己会被提取 |
<usage> | 系统 | token 计数、工具调用次数、耗时 |
实际通知示例(包含所有可选字段):
<task-notification>
<task-id>agent-a1b</task-id>
<tool-use-id>toolu_abc123</tool-use-id>
<output-file>/tmp/claude-uid/proj/session/subagents/agent-a1b.md</output-file>
<status>completed</status>
<summary>Agent "Investigate auth bug" completed</summary>
<result>Found null pointer in src/auth/validate.ts:42. The user field on Session is undefined when...</result>
<usage><total_tokens>12450</total_tokens><tool_uses>8</tool_uses><duration_ms>34200</duration_ms></usage>
</task-notification>Coordinator 看不到 Worker 的中间过程——只能看到通知里封装好的内容。<output-file> 指向 Worker 的完整 transcript 文件,Coordinator 可用 TaskOutput 工具读取。但 Coordinator 的系统提示里故意没有列出 <output-file> 字段——系统提示只教它需要关心的字段(task-id、status、summary、result、usage)。
Scratchpad 机制——Worker 之间的共享文件系统
Coordinator 模式下,Worker 之间不能直接通信(Worker 看不到彼此的对话)。所有信息传递只能走两条路:要么经过 Coordinator 的 prompt 中转(受 context window 限制),要么通过文件系统。Scratchpad 就是后者。
它解决什么问题?
Worker A(研究)产出了大量信息:文件路径、行号、类型签名、调用关系。这些信息如果要传递给 Worker B(实现),传统路径是:
Worker A → <result> 截取 → 注入 Coordinator context → Coordinator 读懂 → 写入 prompt 给 Worker B
这条路径有两个瓶颈:(1) <result> 只保留最终文本,中间过程丢失;(2) Coordinator 的 context window 有限,信息经过一次中转必然被压缩。
Scratchpad 提供了一条旁路:
Worker A → 直接写入 scratchpad 文件(完整、结构化、不受截取限制)
Worker B → 直接读取 scratchpad 文件(获得原始数据,不经过 Coordinator 压缩)
Coordinator 的角色从"信息中转站"变成"轻量协调者"——它只需要告诉 Worker B "去 scratchpad 读 auth-investigation.md",而不需要自己先读懂再复述。
实现机制(源码 utils/permissions/filesystem.ts + constants/prompts.ts):
- 路径格式:
/tmp/claude-{uid}/{sanitized-cwd}/{sessionId}/scratchpad/(per-session 隔离) - 由
tengu_scratchfeature gate 控制 - 目录权限
0o700,仅当前用户可访问 - 路径注入:
getScratchpadInstructions()(prompts.ts:521)作为系统提示的标准 section,注入到所有 Agent 的 system prompt 中。Worker 构建系统提示时经过enhanceSystemPromptWithEnvDetails()(runAgent.ts:918)也会包含这段指令。Coordinator 通过getCoordinatorUserContext()(coordinatorMode.ts:104)额外注入。两边都知道路径。 - 权限自动放行:
isScratchpadPath()检查文件路径是否落在 scratchpad 目录内(含路径遍历防护),命中后自动允许读写,不需要用户确认权限提示。
Worker 的系统提示中包含的具体指令
IMPORTANT: Always use this scratchpad directory for temporary files instead of
/tmpor other system temp directories:/tmp/claude-{uid}/{sanitized-cwd}/{sessionId}/scratchpad/The scratchpad directory is session-specific, isolated from the user's project, and can be used freely without permission prompts.
典型用法
Worker A(研究)→ 将调查结果写入 scratchpad/auth-investigation.md
→ 包含文件路径、行号、根因分析、建议修改方案
Coordinator → 告诉 Worker B:"去 scratchpad 读 auth-investigation.md,按里面的 spec 修改"
Worker B(实现)→ 读取完整的研究结果,获得所有细节,直接开始实现
局限性:Worker 之间没有直接的文件名协调机制。Worker A 不知道 Worker B 需要什么格式、以什么文件名去读。Coordinator 仍需做桥梁——告诉 Worker B 文件名和用途。Scratchpad 解决了"能不能写共享空间"的问题,但没有解决"Worker 之间如何发现和协商共享内容"的问题。
值得质疑的信息瓶颈
Coordinator ↔ Worker 的通信机制存在一个根本性的信息瓶颈问题。
Worker 不知道自己会被截取。 Worker 只是一个正常的 Claude 对话实例,它正常完成任务、正常输出最终文本。系统在背后从 Worker 的最后一条 assistant 消息中提取纯文本,包装成 <result> 字段。Worker 不知道"我需要为 Coordinator 写一份结构化报告"——除非 Coordinator 在 prompt 里显式要求它这么做。
这意味着:
- 结果质量完全取决于 Worker 的最后一条消息。 如果 Worker 的最终输出是 "Done, fixed it" 而不是详细报告,Coordinator 就几乎什么也得不到。Coordinator 系统提示建议在 prompt 里加 "Report specific file paths, line numbers, and types involved",但这只是建议,不是机制层面的保证。
- 中间过程全部丢弃。 Worker 可能读了 20 个文件、跑了 10 条命令、做了大量推理,但 Coordinator 只能看到最后的纯文本输出。所有 tool call 的细节、中间推理步骤都不可见。
- 没有结构化输出保证。
<result>是纯文本,没有 schema 约束。Coordinator 必须从自然语言中解析文件路径、行号等关键信息。 - Coordinator 被迫做有损压缩。 多个 Worker 的结果注入 Coordinator 的 context window 后,Coordinator 要自己读懂、提炼、写成 spec 给下一个 Worker。窗口有限,必然丢失细节。
Scratchpad 部分缓解了这些问题——Worker 可以把完整的结构化信息写入文件,下一个 Worker 直接读取,绕过 Coordinator 的 context window 限制。但如上节所述,文件名协调仍依赖 Coordinator。Claude Code 选择当前方案的合理性在于简单性——Worker 不需要学习新协议,复用标准 Claude 对话能力。但读者应当意识到,这是用提示工程补偿机制缺陷的设计权衡。
4.4 Coordinator 的交互流程示例
用户: "auth 模块有个空指针,能修一下吗?"
协调者:
调查一下。
Agent({ description: "调查 auth bug", subagent_type: "worker",
prompt: "调查 src/auth/ 里的空指针风险..." })
Agent({ description: "调查 auth 测试", subagent_type: "worker",
prompt: "找到所有 auth 相关测试文件..." })
正在从两个方向调查——稍后汇报。
[Worker A 完成通知]
找到 bug 了 — validate.ts:42 空指针。
SendMessage({ to: "agent-a1b",
message: "修复 src/auth/validate.ts:42 的空指针..." })
修复进行中。
用户: "进展如何?"
协调者:
修复进行中,测试那边还在等。
五、Swarm / Agent Teams——团队协作
5.1 是什么
Swarm / Agent Teams 下,多个 Agent 组成团队共同完成任务。通过 --agent-teams CLI 参数激活。
源码中的角色结构:存在一个 team lead(
TEAM_LEAD_NAME),其余成员是 teammates / workers。队员之间可以互发消息,但整个团队模型并不是”完全对等去中心化”——Leader 承担了权限审批、关闭协商、模式切换等系统协调职责。
5.2 通信架构——文件邮箱
每个 Agent 有一个 JSON 文件作为收件箱(teammateMailbox.ts):
~/.claude/teams/{team_name}/inboxes/{agent_name}.json
Agent A 调用 SendMessage 工具 → writeToMailbox() 往 Agent B 的文件里追加一条消息 → Agent B 在下一轮 tool round 通过 useInboxPoller 自动拉取未读消息。
并发安全:写入时带文件锁(lockfile),防止多个 Agent 同时写同一个收件箱。锁有指数退避重试(10 次,5ms-100ms)。
流程:
发送方式(SendMessage 工具的 to 参数):
to 值 | 目标 | 说明 |
|---|---|---|
”researcher” | 指定队友 | 按名字发送 |
”*” | 广播 | 给所有队友发,开销与团队人数线性相关 |
”uds:/path/to.sock” | 跨 session | 本机另一 Claude session(通过 Unix Domain Socket) |
”bridge:session_...” | 跨机器 | Remote Control peer session |
Agent 的纯文本输出不会被其他 Agent 看到——通信必须通过 SendMessage 工具。来自队友的消息自动投递,不需要主动检查收件箱。
5.3 双层消息体系——Agent Team 的精髓
邮箱里存在两类本质不同的消息。这是整个 Agent Team 设计中最关键的设计决策。
第一层:LLM 间聊天(普通文本消息)
Agent 之间自由发送的自然语言消息。格式(TeammateMessage):
{
“from”: “researcher”,
“text”: “auth bug 的根因在 validate.ts:42,Session.user 在 token 过期时为 undefined”,
“timestamp”: “2025-04-01T10:30:00Z”,
“read”: false,
“color”: “red”,
“summary”: “auth bug root cause found”
}这类消息被 formatTeammateMessages() 格式化为 XML,直接注入 Agent 的 LLM 对话上下文:
<teammate-message teammate_id=”researcher” color=”red” summary=”auth bug root cause found”>
auth bug 的根因在 validate.ts:42,Session.user 在 token 过期时为 undefined
</teammate-message>LLM 看到这段 XML,理解它来自 researcher 队友,然后决定怎么回复或采取什么行动。
第二层:系统信令(结构化协议消息)
带有 type 字段的 JSON 消息。这些消息不进入 LLM 的对话上下文,而是被 isStructuredProtocolMessage() 识别,路由到 useInboxPoller 中专门的代码处理器。
| 消息类型 | 方向 | 处理方式 |
|---|---|---|
idle_notification | Worker → Leader | Leader 的 poller 更新 Worker 状态为”空闲可分配” |
permission_request / response | Worker ↔ Leader | Leader 弹权限对话框给用户确认;Worker 的 poller 应用权限决定 |
sandbox_permission_request / response | Worker ↔ Leader | 同上,针对沙箱网络访问控制 |
shutdown_request / approved / rejected | Leader ↔ Worker | Worker 的 poller 处理关闭协商,批准则终止进程 |
plan_approval_request / response | Worker ↔ Leader | Plan 模式下 Worker 提交方案,Leader 审批 |
task_assignment | Leader → Worker | 任务分配通知 |
team_permission_update | Leader → 广播 | 更新所有 Worker 的权限规则 |
mode_set_request | Leader → Worker | 切换 Worker 的权限模式(如从 planEdit 切到 auto) |
为什么要分开?
如果把 permission_request JSON 原样塞给 LLM,LLM 可能会用自然语言”回复”它——“好的,我同意这个权限请求”。但这不是有效的权限处理。权限需要走专门的 UI 流程(弹窗确认、规则匹配、自动批准逻辑),不能让 LLM 自己决定。
分离的核心价值:LLM 只处理它擅长的事(理解语义、做决策、生成自然语言),系统协调逻辑由代码处理。 这避免了 LLM 误解或干预系统级信令。
消息分流示意图
Agent B 的收件箱 (inboxes/researcher.json)
│
├─ { from: “leader”, text: “去修 auth bug”, ... }
│ → 不是结构化协议 → 格式化为 XML → 注入 Agent B 的 LLM 上下文
│
├─ { from: “worker-1”, text: {“type”:”idle_notification”,...}, ... }
│ → isStructuredProtocolMessage() = true
│ → 路由到 idleHandler → 更新状态为”空闲”
│ → LLM 看不到这条消息
│
└─ { from: “leader”, text: {“type”:”shutdown_request”,...}, ... }
→ isStructuredProtocolMessage() = true
→ 路由到 shutdownHandler → 弹出确认 / 自动处理
→ LLM 看不到这条消息
5.4 两种运行方式
| 方式 | 实现 | 优点 | 缺点 |
|---|---|---|---|
| In-process | 同进程,AsyncLocalStorage 隔离 | 轻量,共享 AppState | 生命周期和主进程耦合更紧 |
| Out-of-process | 独立 tmux / iTerm2 窗格,独立进程 | 隔离更强,跨终端可见 | 更重,需要终端后端支持 |
扁平化约束:队友不能再创建队友——团队结构是单层的:
if (isTeammate() && teamName && name) {
throw new Error('Teammates cannot spawn other teammates — the team roster is flat.')
}
5.5 上下文隔离
In-process 队友通过 Node.js 的 AsyncLocalStorage 实现隔离:
type TeammateContext = {
agentId: AgentId,
agentName: string,
teamName: string,
color: string,
planModeRequired: boolean,
parentSessionId: string,
abortController: AbortController,
}同一个进程内的多个 Agent,各自有独立的上下文空间,不会互相干扰。
六、Agent 生命周期
创建
模型调 AgentTool → 解析 AgentDefinition → 决定前台/后台
├ 前台:阻塞当前工具调用
└ 后台:注册为 Task(状态:pending → running)
执行
创建独立上下文 → 独立 AbortController
构建 System Prompt → 根据 Agent 类型定制
过滤工具池 → Explore 只给只读工具
调用 query() → 启动独立的 Think→Act→Observe 循环
完成
提取最终文本作为 Tool Result
├ 前台:直接返回给主 Agent
└ 后台:发送 <task-notification>,更新 Task 状态(completed/failed/killed)
清理:断开 MCP、归档 transcript、停止进度追踪
Task 状态机
pending → running → completed
→ failed
→ killed(被 TaskStop 或 AbortController 取消)
七、ToolSearch:当 Agent 有太多工具可用
问题
MCP 服务器可能注册几十甚至上百个工具。全部发完整 schema 给 API,光工具定义就占几万 token。
解决方案:延迟加载
把工具分成两类:
| 类型 | 发给 API 的内容 | 举例 |
|---|---|---|
| 核心工具 | 完整的 name + description + input_schema | Bash、Read、Edit、Agent 等 |
| 延迟工具 | 只有名字 + defer_loading: true | 大部分 MCP 工具 |
模型想用某个 MCP 工具时,先调 ToolSearch 工具搜索,拿到完整 schema,API 下一轮自动注入。
ToolSearch 的检索算法
纯本地关键词检索,不调用 LLM,不用向量数据库:
1. 解析 query
select:mcp__github__create_issue→ 精确选取,跳过搜索github issue→ 关键词搜索+github send→github必须匹配,send用于排序
2. 拆解工具名
mcp__github__create_issue → ["github", "create", "issue"]
ToolSearch → ["tool", "search"]
3. 逐工具打分
| 匹配位置 | 匹配方式 | 得分 |
|---|---|---|
| 工具名词元 | 精确匹配 | 普通工具 10 分,MCP 工具 12 分 |
| 工具名词元 | 部分包含 | 普通工具 5 分,MCP 工具 6 分 |
| searchHint | 词边界匹配(工具自带的一句话标签) | 4 分 |
| description | 词边界匹配(工具完整描述) | 2 分 |
MCP 工具名字匹配加权更高,因为 MCP 工具名本身包含服务器名和操作名,信号更可靠。
4. 排序返回
按总分降序,取前 N 个(默认 5 个)。返回 tool_reference 块,API 自动注入完整 schema。
八、总结:Claude Code Agent 架构的设计原则
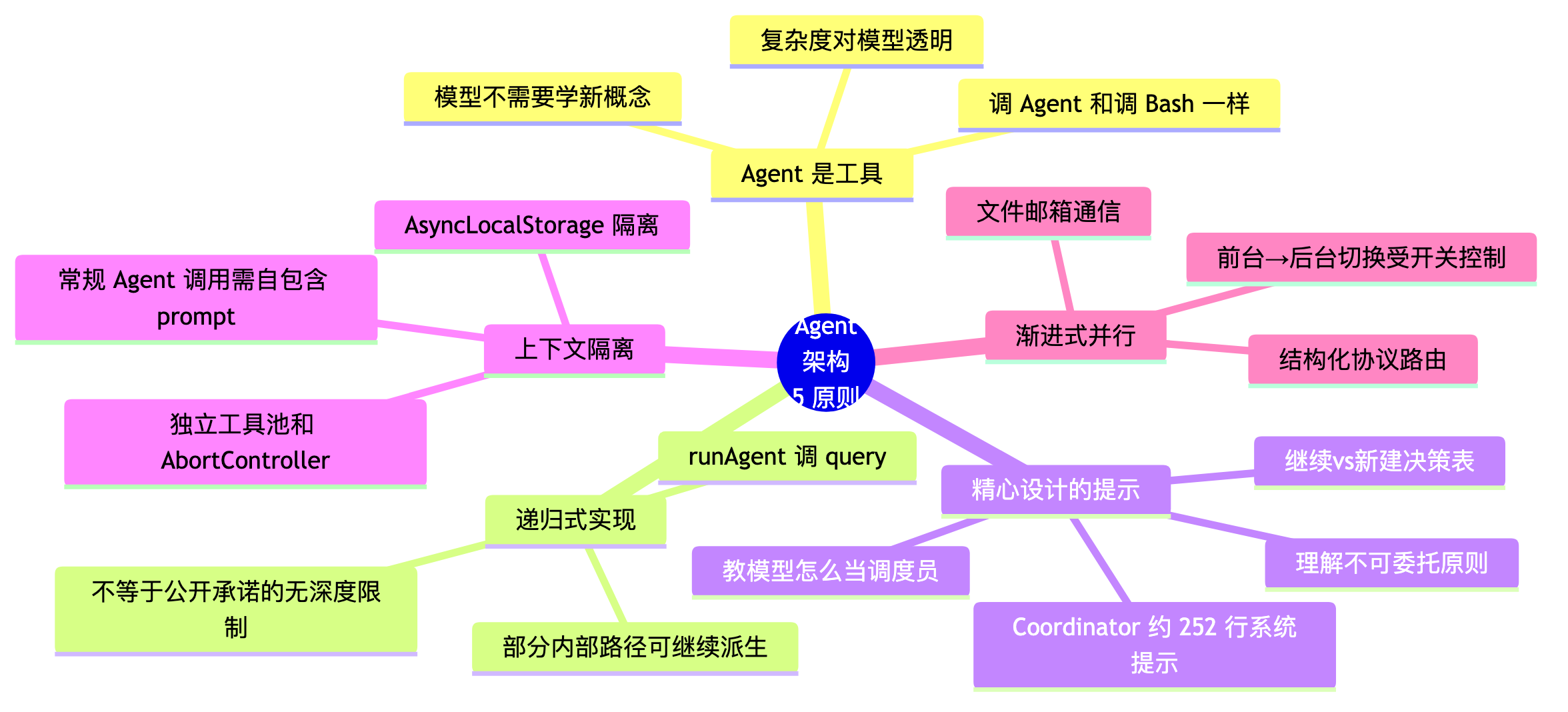
原则 1:Agent 是工具,不是新概念
把多 Agent 系统简化成模型已经擅长的事——调工具。模型不需要理解"Agent"是什么,只需要知道"调 Agent 工具,传 prompt,等结果"。
原则 2:递归式实现统一了多种内部路径
runAgent() 调 query(),这是 Claude Code 在内部复用 Agent 机制的重要方式。但不要把这直接等同于“对外公开支持无限层子代理”。更稳妥的结论是:Claude Code 用同一套 Agent 基础设施覆盖了前台子代理、后台子代理、Coordinator worker、部分 fork 路径等多种场景。
原则 3:提示工程是 Agent 编排的关键
Coordinator 的 370 行系统提示不是"你是个协调者"这么简单。它定义了标准工作流阶段、强制理解不可委托、给出决策表、提供好坏示例。大部分 AI 编排系统失败在提示太模糊——模型不知道什么该做什么不该做。
原则 4:用上下文隔离减少干扰
每个子代理通常有独立的系统提示、工具池和 AbortController;常规 Agent 调用也应按“fresh start”来编写 prompt。这套设计能有效减少干扰。但如果讨论到 fork 等内部路径,就不能再简单概括成“所有子代理都只看到孤立 prompt”。
原则 5:并行有度,异步有通知
前台 Agent 阻塞等结果,后台 Agent 异步运行并通过 <task-notification> 通知。Coordinator 模式下还可以通过 scratchpad 共享知识。团队模式则用邮箱协议区分普通消息和结构化协议,避免模型误解。
附录:关键源码文件索引
| 关注点 | 文件路径 |
|---|---|
| Agent 工具入口 | src/tools/AgentTool/AgentTool.tsx |
| 子代理执行 | src/tools/AgentTool/runAgent.ts |
| 内置 Agent 定义 | src/tools/AgentTool/built-in/ |
| 自定义 Agent 加载 | src/tools/AgentTool/loadAgentsDir.ts |
| Coordinator 系统提示 | src/coordinator/coordinatorMode.ts |
| 邮箱系统 | src/utils/teammateMailbox.ts |
| Agent 上下文隔离 | src/utils/agentContext.ts |
| 队友上下文 | src/utils/teammateContext.ts |
| 后台代理摘要 | src/services/AgentSummary/agentSummary.ts |
| SendMessage 工具 | src/tools/SendMessageTool/SendMessageTool.ts |
| TeamCreate/Delete | src/tools/TeamCreateTool/、src/tools/TeamDeleteTool/ |
| ToolSearch 检索 | src/tools/ToolSearchTool/ToolSearchTool.ts |
| 工具注册中心 | src/tools.ts |
| Agent loop | src/query.ts |
| In-process 队友 | src/tasks/InProcessTeammateTask/ |
声明:本文基于公开 npm 包的 source map 还原代码分析,仅供参考和学习。凡涉及内部开关、实验特性、后台阈值、团队实现细节等内容,均应理解为“当前源码所示”,不代表 Anthropic 对外承诺的稳定产品规范。源码版权归 Anthropic 所有。